Продукты под брендом SharxDC:
Сегодня мероприятие ведет Константин Шамрай, генеральный директор, «Шаркс Датацентр».

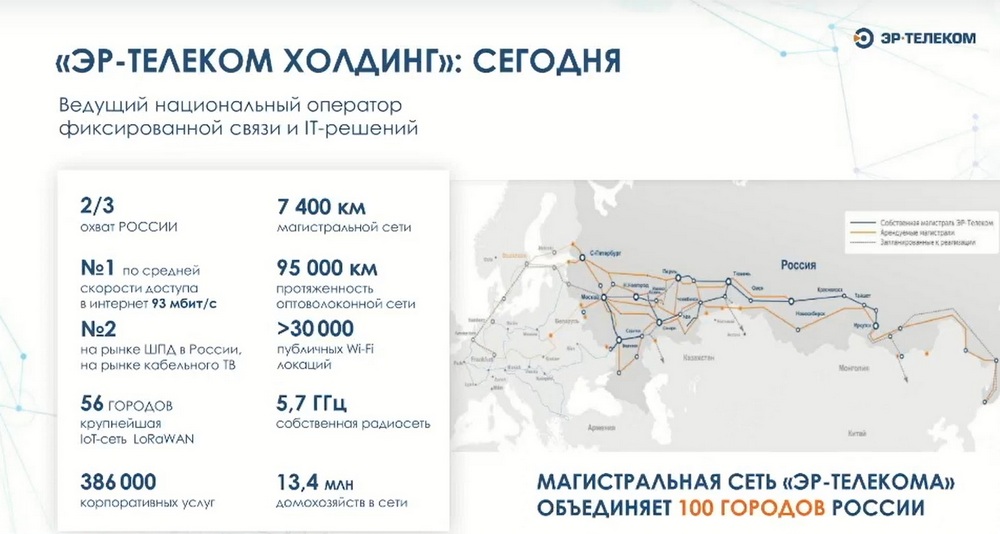
Компания «Шаркс Датацентр» - это российская компания разработчик ПО в области виртуализации и гиперконвергенции. Она на рынке присутствует с 2015 года, с 2022 года компания стала частью холдинга «ЭР-Телеком».
Ключевым решением «ЭР-Телеком» является платформа виртуализации SharxDS.

Компания «Шаркс Датацентр» поставила перед собой задачу: все решения, которые разрабатывают ее сотрудники должны быть включены в российский реестр ПО.

Все три продукта SharxDS внесены в реестр отечественного ПО, а на решение SharxBase получен сертификат ФСТЭК на 4-й уровень доверия. Решение, предлагаемое компанией «Шаркс Датацентр», полностью закрывает вопрос импортозамещания продуктов виртуализации.

В случае продажи ПАК и ПО сервисное обслуживание осуществляется компанией «Шаркс Датацентр», она обеспечивает техподдержку 24х7 с временем реакции 4 часа. Среди российских партнеров аппаратного обеспечения можно выделить три ключевые компании: Ядро, Аквариус и Крафтвэй. С ними проведен полноценный цикл тестирования их аппаратных платформ и у«Шаркс Датацентр» плотное взаимодействие с их группами разработки.
SharxBase – это платформа виртуализации, гиперконвергентное решение, которое объединяет в себе виртуализацию как вычислительных ресурсов, так и ресурсов хранения. За счет архитектурных особенностей система не имеет единой точки отказа и предназначена для создания различных инфраструктур, которые должны обеспечивать высокодоступное решение для запуска различного рода ИС.

На слайде приведены отличительные особенности системы. Одним из основных кейсов является решение по созданию инфраструктуры виртуализации, которые позволят создавать виртуальные ЦОДы и виртуальные платформы. За счет того, что система построена на базе современного оборудования с использованием SSD-накопителей – данная архитектура позволяет обеспечивать функциональные возможности для запуска различных кластеров аналитики и высоконагруженных баз данных.
За счет использования средств SharXDesk на платформе можно реализовывать полноценную инфраструктура VDI. Нами разработаны три продукта SharXBase, SharXstorage и SharXDesk.
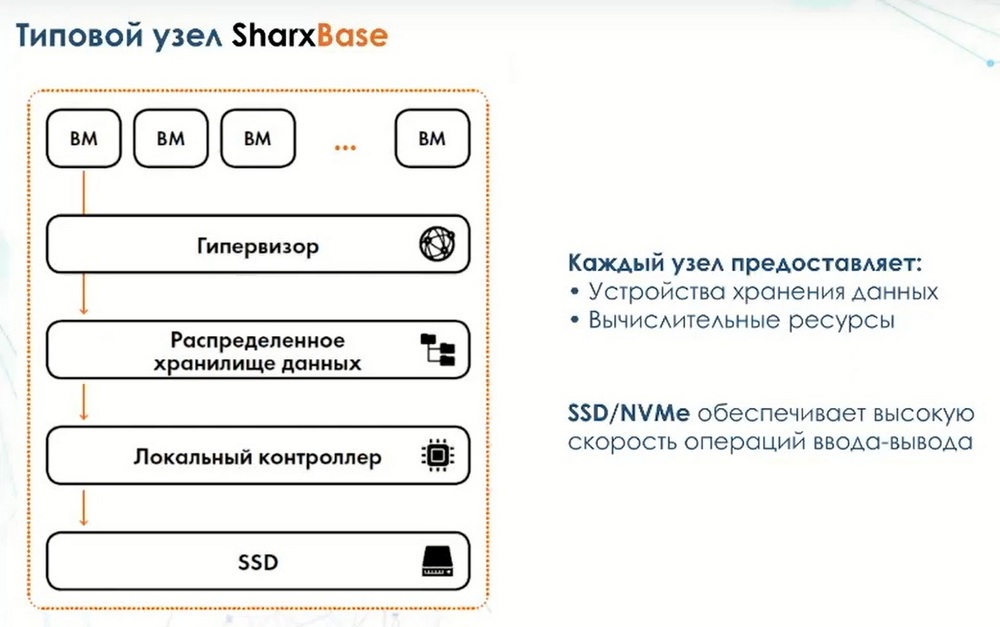
Что из себя представляет платформа SharXBase? Это серверная платформа х86 архитектуры, предпочтение есть у российских серверов, входящих в реестр, но могут использоваться решения китайских производителей и другие решения, например Intel и AMD. В каждом узле установливаются SSD-накопители, отдельно устанавливаются загрузочные устройства, на которые устанавливается гипервизор, затем устанавливается ОС и ПО компании «Шаркс Датацентр» и впоследствии реализуется весь функционал платформоуправления.
Эта архитектура легко масштабируется и минимально в системе должно быть абсолютно идентичных 4 узла.

В этом случае нет единой точки отказа. Кластерное ПО позволяет отслеживать состояние всех критически важных сервисов. На уровне архитектуры исключена проблема, связанная с поддержкой кластера. Для расширения функциональности есть распределенное хранилище, которое запускается в виде сервиса и представляет собой блочное устройство внутрь виртуальных машин, которые могут запускаться на физических узлах.
Для защиты данных используется механизм тройной репликации, каждый блок данных записывается на три произвольных узла. В этом случае, даже если упадут два сервера, данные останутся доступными и виртуальные машины будут функционировать. Для оркестрации выпускается отдельный сервисный контейнер, в котором есть интерфейс управления. Внутри самого сервер-контейнера с оркестратором нет никаких служебных данных. Они хранятся тем же методом, что хранятся пользовательские данные на распределенных хранилищах. В этом случае, в случае выхода из строя любого из узлов, сервисный контейнер может быть перезапущен на абсолютно любом узле и функциональность среды управления будет восстановлена в кратчайшие сроки. За счет того, что система является горизонтально масштабируемой, можно как добавлять узлы, так и исключать их из состава кластера. Это позволяет добиться определенного рода легкой масштабируемости и расти по мере возникновения потребности в этом. Поэтому минимально рекомендуемой конфигурацией является конфигурация в четыре узла. Далее из нее можно будет вырасти в большую инсталляцию.
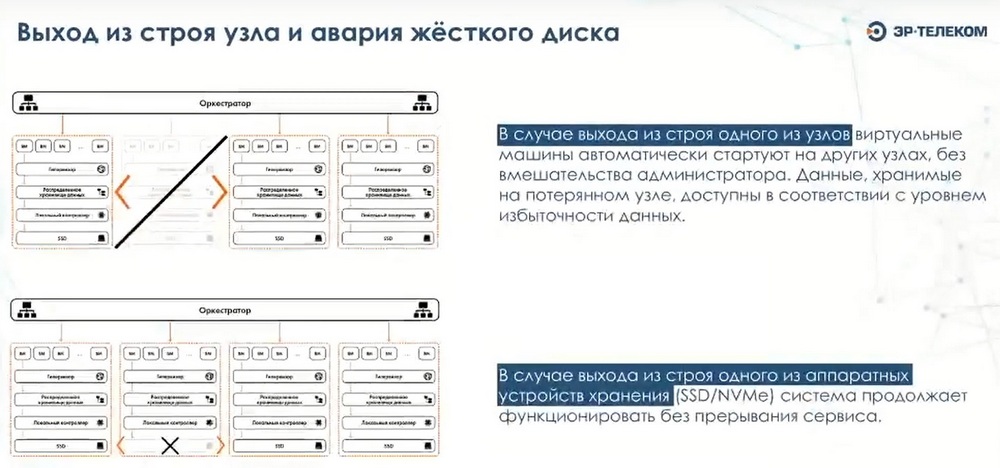
Мы используем механизм трехкратной записи данных. Это позволяет нам исключить вариант того, что выход из строя любого узла приведет к недоступности какой-либо функциональности. Функциональность вся будет восстановлена, и нет никаких сервисов, которые запущены на каком-либо узле и являются прикрепленными к ней.
Для подключения жестких дисков не нужен RAID-контроллер, можно использовать FBH, и они пробрасываются напрямую. Нам не нужна организация рейда на уровне аппаратного контроля.
Четыре сервера являются рекомендуемой конфигурацией для того, чтобы начать строить кластер, но минимально доступная конфигурация - три узла. И в этом случае есть единственное ограничение, что в случае выхода из строя одного из узлов, система будет продолжать работать, но сможет создавать новые виртуальные машины до тех пор, пока не будет введен в эксплуатацию третий узел. Потому что мы не сможем обеспечить тройную запись на три различных сервера. Для существующих виртуальных машин функционирование будет обеспечиваться, и там все будет писаться. После добавления триера ввод в эксплуатацию третьего узла после аварии, данные будут синхронизированы и функциональность будет восстановлена в полном объеме.
По поводу сервисов, которые могут быть запущены и будут запущены автоматически. Контейнерные сервисы запускаются все автоматически в случае выхода из строя одного из узлов. И это является функцией кластерного ПО. В случае выхода из строя одного из серверов, система отслеживания живости именно физических узлов определяет с определенным лагом, потому что сервер является физически недоступным, пытается его реанимировать. Если не удается его реанимировать, то в этом случае все виртуальные машины, которые были запущены на этом сервере, будут перезапущены в автоматическом режиме на других узлах. Перезапуск осуществляется тоже в автоматическом режиме.
Вопрос. В случае выхода из строя жесткого диска, мы его заменяем, и запускаем процедуру ребаллансировки данных для того, чтобы восстановить отчетность для тех данных, которые были на вышедшем из строя диске. Никаких вопросов здесь не возникает. В случае добавления нового узла в кластер, он добавляется автоматически. Они сразу же доступны для размещения на них пользовательских данных. В случае выхода из строя узла, предварительно выполняются различные сервисные процедуры, которые говорят о том, что этот узел будет выведен из строя, данные с него релоцируются, третьи копии делаются на других узлах, и после завершения этой процедуры, этот узел может быть удален из состава кластера.
Это пример минимальной инсталляции. У нас конфигурация должна включать в себя три узла, три сервера. В этом случае в зависимости от аппаратной конфигурации можем получить до 160 vCPU и 2,1 Тбайт RAM и 236 Тбайта доступного дискового пространства.

Для обеспечения сетевого интерконнекта, мы используем две сети, которые необходимы. Первая - сеть передачи данных. Она построена на базе коммутаторов 25/50. Это рекомендуемая конфигурация. Есть выделенная сеть управления, к которой подключены все ABI-интерфейсы, и которая как раз используется для отслеживания корректности функциональности хостов и живости их. Потому что мы можем выводить узлы в обслуживание, либо узел может быть по каким-либо причинам перезапуститься, но после этого он автоматически поднимается. Если же узел вышел из строя, и если он недоступен в течение определенного времени, обычно это 3 минуты, то машины начинают запускаться на других кластерах. Т.к. хранилище распределенное, то все данные будут доступными.
Если на узле были запущены управляющие сервисы, которые имели VIP-адрес, то этот сервисный контейнер будет кластерным софтом перезапущен на другом узле с сохранением своего VIP-адреса.
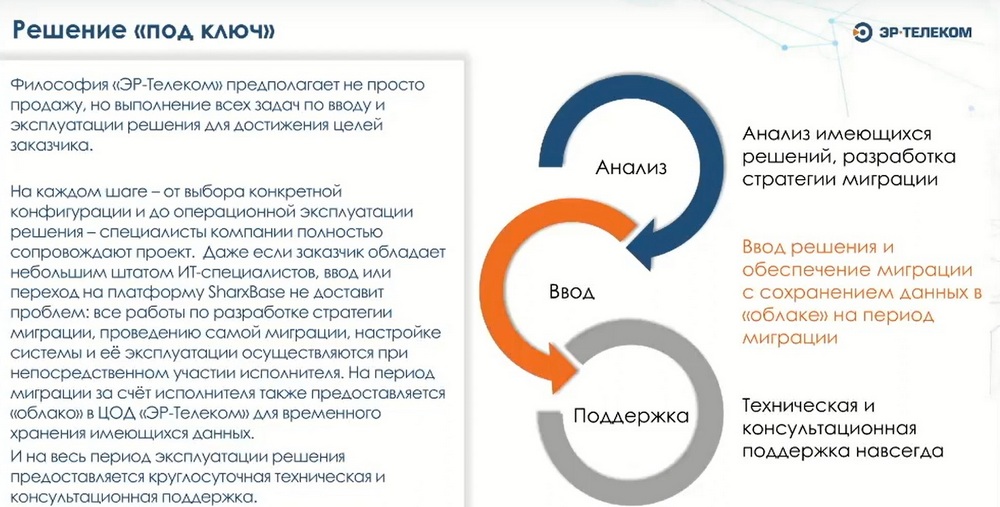
Мы с помощью нашего ПО и ПАКов, выпускаемых на базе ПО компании «Шаркс Датацентр», предлагаем решение под ключ, готовы оказывать консультационные услуги по проектированию инфраструктуры и помогать в имплементации этих решений. Помогаем мы и по процедурам инсталляции, это входит в базовый пакет, мы можем произвести у клиента инсталляцию удаленно.
В стандартный пакет входит реакция 24 на 7 на приоритеты 1-го и 2-го уровня (соответственно, когда система полностью не доступна, наблюдается сильная просадка производительности), в остальных случаях реакция будет 9 на 5.
Примеры некоторых реализованных проектов представлены на следующих двух слайдах.


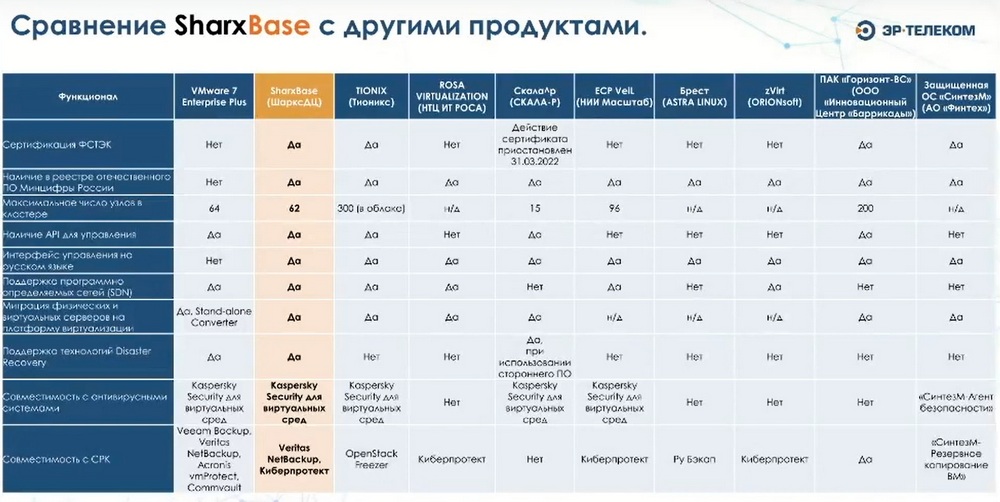
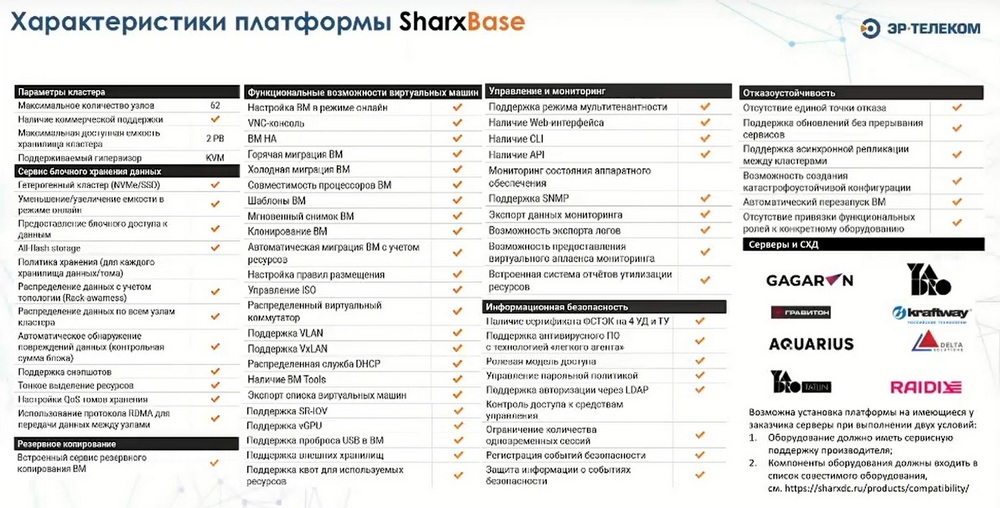
На следующем слайде приведено сравнение ПО компании с конкурирующими продуктами и характеристики SharxBase.