Сегодняшнее мероприятие, посвященное оценке рисков на основе анализа данных, полученных из DLP-систем, ведет Степан Дешевых, руководитель отдела развития продуктов, компания InfoWatch.

Пандемия и массовая удаленная работа стали катализатором ускорения коммуникаций в цифровом виде. В этот период у служб информационной безопасности значительно прибавилось работы: резко возросло количество каналов, которые нужно контролировать, и событий, которые нельзя пропустить в потоке данных. Стало понятно, что разбирать инциденты вручную постфактум не эффективно, даже если это делается хорошо. А чтобы показывать эффективность ИБ, нужно управлять рисками и прогнозировать их. Эту задачу пока осваивают в службах информационной, экономической и кадровой безопасности.
Сегодня речь пойдет о том, какие подходы и методики анализа данных в DLP-системах можно и нужно использовать для решения таких задач. Как применять DLP для оценки кадровых и экономических рисков. И какие возможности дает предиктивная аналитика в DLP для того, чтобы вы могли быстро и в автоматическом режиме приоритезировать инциденты, фокусироваться на главном, собирать цельную картину из множества разрозненных событий и оценивать риски.
Степан Дешевых привел оценку того, что происходит на ИБ-рынке, как именно меняются DLP-системы, как меняется окружение, в котором они работают, к каким последствиям это приводит. Как на DLP сказались изменения ландшафта коммуникаций, чем в работе с DLP помогают Business Intelligence, машинный анализ и предиктивная аналитика, что это дает службам информационной и экономической безопасности.

Какие проблемы возникают в этой части, какие подходы есть к решению возникающих проблем. Что приходится делать, чтобы отвечать на современные вызовы.
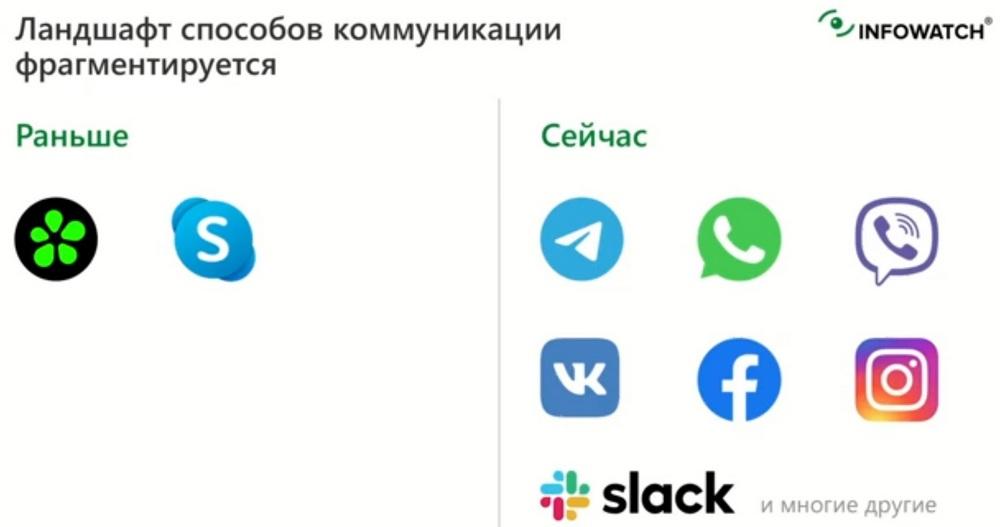
Каналы коммуникаций
Раньше защищать каналы коммуникация было много проще, поскольку их было значительно меньше: электронная почта, «Аська» и чуть позже появился Skype. Сейчас же количество мессенджеров и способов коммуникаций стало много больше и их число продолжает расти быстрыми темпами. Мессенджеры становятся специализированными, такими как «Телеграмм», WhatsApp, есть китайские мессенджеры, появляются рабочие специализированные, например, slack. Также как из неоткуда возникли социальные сети: Facebook, «Вконтакте», Instagram и т.д., которые тоже могут использоваться в качестве мессенджеров как для работы, так и для простого общения. Для ИБ-профессионалов все это представляет определенный интерес. Для производителей DLP-систем – это все представляет большую проблему, потому что чем больше на поддержке каналов, тем сложнее выпускать обновления, поскольку мессенджеры постоянно меняют свои протоколы и периодически съем данных с мессенджеров «ломается».
Мы решаем эту проблему технологически: готовим технологию контроля приложений, позволяющую абстрагироваться от используемых протоколов и следить за тем, какая информация приходит в приложение, это с одной стороны, а с другой стороны мы еще и получаем возможность посмотреть на эту проблему чуть иначе.
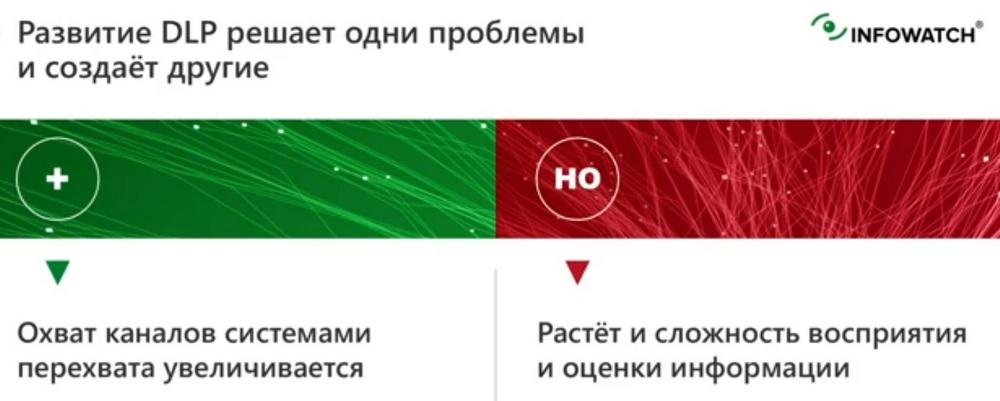
Мы «догоняем» эти каналы с точки зрения их количества, с точки зрения сообщений, которые нам удается перехватить, но в то же время слишком много событий появляется в самой DLP-системе, а в них разбираться становится довольно сложно, найти что-то важное – еще сложнее. И для того, чтобы эту проблему решить мы придумали специализированную систему, которую назвали Vision.

Vision – это Business Intelligence для DLP. Эта система позволяет посмотреть на данные в целом, позволяет визуализировать данные в виде отчетов и графов связи в агрегированном виде.
Целеуказание
Агрегация позволяет увидеть некие паттерны, увидеть не просто отдельные события, перечень которых пролистать невозможно, но увидеть и реальную статистику. Увидеть реальные аномалии собственными глазами. Vision помогает вести цифровое досье сотрудников, а также поддерживает специалистов InfoWatch при проведении расследований. В общем, инструмент удобный, но и с ним тоже есть определенные проблемы. Данных очень много и непонятно, с какой стороны лучше заходить. Откуда и куда копать? Из-за того, что данных очень много, не очень понятно, за что хвататься в первую очередь. Из-за перегрузки данными «за деревьями не видно леса». Когда у вас 1000 сотрудников, кого просматривать в первую очередь? Vision сам по себе на эти вопросы ответа не даст. И тогда нам пришла в голову идея, что неплохо бы дополнить инструменты визуализации еще и инструментами целеуказания. И вот в этом контексте мы развиваем Prediction.

Основная его задача состоит в том, чтобы в потоке событий выявить на данный момент самое важное, обратить внимание ИБ-сотрудника на потенциальные или реализующиеся в текущий момент угрозы. Например, кто-то собирается уволиться, кто-то выводит информацию из компании. И по целеуказаниям от Prediction уже можно покопаться в данных из Vision и посмотреть, что происходит. Области применения Prediction, в первую очередь, следующие: это информационная безопасность, экономическая безопасность и более общая задача - выявление аномалий в повседневной жизни.
А теперь чуть подробнее о том, как InfoWatch это делает.

Внутри концепции этого продукта лежит идея распределения сотрудников по группам риска. Т.е. мы можем "пометить" сотрудника, например тем, что он занимается поиском работы. Возможно у него есть слишком личные связи с контрагентами, что особенно важно для отдела закупок, когда надо оценить экономическую безопасностью. Возможно, у сотрудника есть финансовые сложности, а это уже уязвимое место. Это значит, что либо человек сам может сделать что-то не очень хорошее, либо его могут спровоцировать это сделать. Есть еще одна группа риска: жизнь не по средствам. Бывает так, что рядовой сотрудник интересуется очень дорогими автомобилями, или постоянно ездит на фешенебельные курорты. Само по себе это совсем неплохо, особенно, если у него есть состоятельный супруг или супруга. Тогда это объяснимо, но бывает так, что никаких очевидных источников дохода для поддержания роскошной жизни у сотрудника нет, а тем не менее непомерные траты у него почему-то происходят. Неплохо было бы выяснить, откуда он берет такие средства. И еще одна группа риска - это слишком личные отношения на работе. Здесь может возникнуть и канал утечки информации, когда близкому человеку рассказывают много лишнего, это может быть и некая слабость, как точка давления на высокопоставленного сотрудника.
Как система раскладывает по группам риска
В первую очередь тут используется анализ переписки в корпоративных каналах связи. Мы можем использовать анализ постов и комментариев в соцсетях. Мы ничего не взламываем, мы пользуемся только открытой информацией. И на все это мы накладываем наши алгоритмы лингвистического анализа и используем простой статистический анализ. В целом, опираясь на ряд признаков, мы можем наших сотрудников по группам риска разложить, и уже в соответствии с тем, как мы пометили сотрудников, провести соответствующую работу по анализу происходящего. Это одна из первых идей. Собственно, а как мы это делаем?
Подход №1 - психотипирование
Этот подход используют наши конкуренты.

Собственно, у конкурентов идея состоит в том, что по анализу переписки, по анализу сообщений, они могут отнести сотрудника к какому-то психологическому профилю, и в соответствии с этим профилем, «подсветить» риски, связанные с этим сотрудником.
В чем преимущества такого подхода? С одной стороны, за этим стоит какая-то научная база, интересно посмотреть, какие особенности характера влияют на поведение сотрудника. С другой стороны, эта информация является статической. Т.е. вы, например, получили группу «технологический профиль сотрудника», но не понятно, что с этим делать. Как его использовать в повседневной работе безопасника?
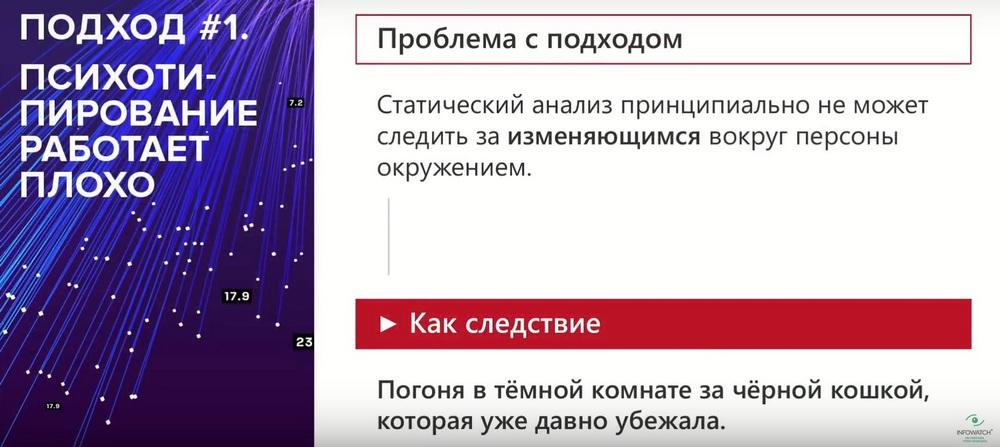
Именно по этой причине мы этот подход не используем. По большому счету знание технологического профиля мало что дает. Тут начинаются гонки за "черной кошкой в темной комнате", когда кошка оттуда уже убежала. Самое важное - это динамически меняющиеся обстоятельства, складывающиеся вокруг подсвеченного сотрудника. Сегодня у него происходит одно, завтра - другое. Безусловно, какие-то внутренние установки у него не меняются, но в зависимости от того, какое у него окружение, меняется и его поведение. А вот такой подход на изменяющееся окружение реагирует очень слабо. И еще любопытный факт.

Мы провели патентное исследование и обнаружили, что психотипирование как технология оценки рисков, развивается очень слабо. Фактически никто не патентует эту тему. А отсутствие интереса к патентованию означает, что и технологического и коммерческого интереса для наших клиентов там нет. Поэтому этот подход мы не используем.
Подход №2 - машинное обучение
Есть другой подход. Называется он machine learning или машинное обучение.

В чем его суть? Мы учим компьютер находить повторяющиеся паттерны, а потом подсвечивать отличия от этих паттернов. То есть, если, например, у нас сотрудник обычно пишет каждый день 5 писем, а теперь вдруг начал писать ежедневно 50, то интересно посмотреть, что же явилось тому причиной? Отличительным свойством алгоритма машинного обучения является то, что машина не устает анализировать. Человек может проанализировать 3, 5, 10 параметров и устанет. В конце концов его голова перестанет вмещать огромное количество переменных. А при машинном обучении могут одновременно анализироваться сотни параметров. И прелесть состоит именно в том, что алгоритмы сами находят значимые параметры, а также учатся следить за их изменениями. Это особенно хорошо работает для оценки того, собирается ли человек уволиться, или нет.
Но с этим подходом есть и определенные сложности. И первая из них, состоит в том, что нужно собирать довольно большое количество обучающих выборок для того, чтобы машинное обучение начало свою работу.

Для этого нужны десятки, а лучше даже сотни объектов. Что здесь подразумевается под объектом? Например, сотрудники, которые уволились. Прежде чем при помощи машинного обучения система научится выявлять сотрудников, которые собираются уволиться, нужно для обучения системы иметь большое количество уволенных сотрудников.
Вторая сложность состоит в том, что описать словами то, как работают алгоритмы машинного обучения, наверное, можно, но понять, по каким причинам, и как именно они выбирают показатели, будет достаточно сложно, а порой просто невозможно. Да и объяснить сотруднику, который смотрит на результаты работы машинного обучения, довольно сложно. Для некоторых людей это выглядит, как некая магия. Понять логику работы машинного обучения тяжело.
Третья сложность - это изменяющиеся бизнес-процессы. Вернемся к приведенному выше примеру о 5 и 50 письмах. Почему сотрудник стал писать 50 писем, а не 5, как прежде? А просто потому что изменился бизнес-процесс. А раз он изменился, извольте начать обучать машину заново. Снова проходим длительный этап обучения, снова создаем контрольную выборку, и машину перенастраиваем.
И четвертая сложность. Те знания, которые формируются в процессе машинного обучения, специфичны для конкретной компании. Их нельзя просто взять и перенести в другую компанию, отмасштабировать, чтобы оно тут же заработало. Ничего подобного не происходит.
Тем не менее, у машинного обучения есть большие преимущества.

Это, во-первых, возможность анализировать неочевидные взаимосвязи между параметрами. И во-вторых, это универсальная применимость алгоритма. Мы можем искать аномалии не только в переписках, но и в мессенджерах. И можем относить алгоритм поиска аномалий не только к сотруднику, но и, например, к компании-конрагенту. Т.е. здесь есть простор для творчества, это вполне жизнеспособная история.
Продолжим подход №2. Здесь можно использовать машинное обучение для автоматизации настройки InfoWatch Traffic Monitor.

Т.е. где работает машинное обучение? Например, когда мы создаем специализированное БКФ (базу контактной фильтрации - это лингвистический алгоритм категоризации собственных документов) для наших клиентов. В чем преимущество? У нас сотрудник, который помогает настроить систему, не видит конфиденциальных данных, с которыми работает. И это хорошо! При этом по качеству на выходе получаются настройки, которые неотличимы от качества работы живого человека, который сам пролистывает эти документы, выводит какие-то важные вещи, их использует. Вот поскольку это довольно стабильная штука, то машинное обучение работает просто отлично. Пожалуйста, пользуйтесь, если нужно настроить систему без участия человека. Сейчас это стало возможным.
И еще один кейс, где можно использовать машинное обучение, это появление признаков того, что сотрудник собирается уволиться. Как это выявить? Это делается с помощью того, что в почте сотрудник начинает вести себя так, как до этого вели себя уволившиеся сотрудники. Здесь можно использовать машинное обучение для автоматизации настройки InfoWatch Prediction.

Здесь мы не можем похвастаться 100%-й точностью, однако достаточно высокая надежность здесь обеспечена. Например, если у нас 10 сотрудников увольняются, то четверых из них мы точно подсветим. И именно те, кого мы подсветили, с очень высокой вероятностью уволятся. Если мы сотрудника подсветили, то точно на него стоит обратить внимание, оценить что у него за проблемы. В этом смысле алгоритмы machine learning работают неплохо.
Подход №3 - анализ цепочек событий
Третий подход, который использует компания InfoWatch для выявления аномалий, для подсветки того, что происходит, это анализ цепочек событий. О чем идет речь?
Мы общаемся с нашими клиентами, с нашими аналитиками, которые помогают внедрить DLP-систему, и фактически перекладываем те факторы, которые они умеют замечать глазами, в алгоритмы. Чаще всего это выглядит в виде цепочек каких-то событий.

На чем строится подход? Во-первых, мы собираем как можно больше событий о том, что происходит в системе. Чем больше событий, тем лучше. Мы используем знания наших клиентов, наших коллег о том, какие события являются значимыми, что они означают. Для каждой угрозы мы составляем так называемый профиль, в котором описываются те самые цепочки событий и их значение. И, соответственно, мы этот профиль включаем в продукт, и уже автоматически можно находить угрозы у клиентов.
В чем преимущества этого подхода? Он довольно простой. Его недостаток состоит в том, что очень сложные цепочки, которые может выявлять МО, мы здесь не найдем.

Тем не менее подход простой, он отлично работает. Потому что в этом случае легко объяснить, почему данную угрозу мы считаем именно угрозой. Эти цепочки событий могут аккумулироваться. Мы, как поставщик решений, их перепродаем нашим клиентам, и они могут пользоваться внешними паттернами знаний, внешними знаниями других безопасников для того, чтобы решать свои проблемы. Эти цепочки легко настраивать самостоятельно, если у вас есть свои уникальные паттерны.

Вот пара примеров. Пусть система настроена таким образом, что сотрудники могут выводить небольшую порцию информации каждый день. Словом, небольшой вывод информации не считаем проблемой. Условно, до 5 Мбайт. Но если у нас появляется сотрудник, который об этом знает, и каждый день он будет выводить ровно по 45 Мбайт, то за 10 дней он сможет унести уже 450 Мбайт. Это может оказаться довольно значимым. И, если анализировать эти события по одному, то они покажутся весьма заурядными, разрешенными к использованию.

Но если мы посмотрим на картинку, то в целом окажется, что у нас сотрудник Сидоров за 10 дней утащил 450 Мбайт. Стоит ли на это обратить внимание? Безусловно, да.
Вот еще один предельно простой пример. Это для информационной и экономической безопасности. Есть несколько подходов для компаний, которые проявляют признаки так называемых «прокладок».

Здесь есть несколько подходов. Часто жулики попадаются на совсем простых и глупых ошибках. Например, отправляют разные КП-шки с одно и того же адреса. Или во время общения с контрагентами во время проведения конкурсов, интенсивность общения между компаниями может быть существенно разной. Вот фирмы-прокладки характеризуются тем, что они обычно не ошибаются. Они всегда представляют КП вовремя, КП правильно составленное, которое не надо возвращать, и поэтому в этом случае интенсивной переписки не ведется.
Еще один вариант, на который имеет смысл обратить внимание, это отсутствие поздравлений. Фирма-прокладка не будет поздравлять своего партнера с Новым Годом, с днем рождения, с 8 марта и т.д. потому что никакого другого, кроме формального взаимодействия, у нее не возникает. Потому что ей это просто не нужно.
Как только мы имеем ряд признаков, можем обратить внимание на то, что происходит, и тогда можем разобраться детальнее. Есть ли там что-то серьезное или нет. Опять же, если анализировать эти события вручную, то непонятно, куда копать. Когда у нас есть механизм, который позволяет эти цепочки событий собрать вместе, проанализировать и подсветить, это существенно упрощает работу безопасников в системе, которая перегружена событиями.

Компания InfoWatch развивает свои продукты с той целью, чтобы облегчить работу клиентов. InfoWatch Activity Monitor в первую очередь собирает и протоколирует действия сотрудников. InfoWatch Traffic Monitor осуществляет контентный анализ и сбор событий по сети. InfoWatch Vision позволяет визуализировать данные, провести анализ, поддерживает расследования. InfoWatch Prediction осуществляет целеуказание на возможные проблемы.

Наш новый продукт InfoWatch Prediction применим для решения широкого спектра задач, и включает в себя алгоритм машинного обучения, позволяет выявлять паттерны и отклонения от них, включает в себя анализ цепочек событий, статистический анализ, который позволяет выявлять цепочки событий, говорящих о том, что возможна какая-то проблема.