Начал презентацию, касаемую «железа» для решения ИИ-задач, Александр Шумилин, менеджер по серверным продуктам Hewlett Packard Enterprise в России. Сегодня речь пойдет о специализированных серверах. Если заказчик их использует, значит перед ним стоит сложная, нетривиальная задача, для которой не подходят стандартные корпоративные решения, и для решения которой виртуализация, классические облака не являются подходящим вариантом.

Вот по такому плану будет развиваться презентация эксперта.
- Серверы HPE Apollo для вычислений
- Платформа NVIDIA TESLA
В первой части выступления речь пойдет о серверах, которые вендор Hewlett Packard Enterprise объединяет под общим названием Apollo.
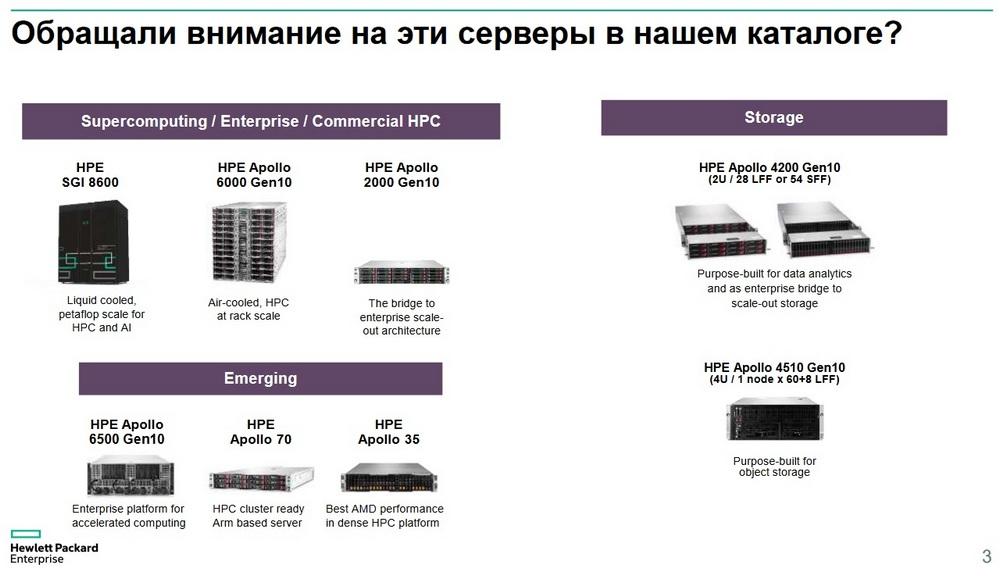
У HPE есть серверы для вычислительных кластеров, для более компактной замены стандартным серверам рэкового исполнения и есть серверы, которые подходят для систем хранения данных.
HPE Apollo 2000
Начнем с наиболее простой платформы Apollo 2000. Это двухюнитовое шасси, в которое устанавливается 4 двухсокетных сервера, по сути это замена четырех одноюнитовых двухсокетных серверов DL 360. В этом сервере будет меньше слотов памяти, но, обычно, очень мало заказчиков забивают полностью слоты памяти серверов DL 360.
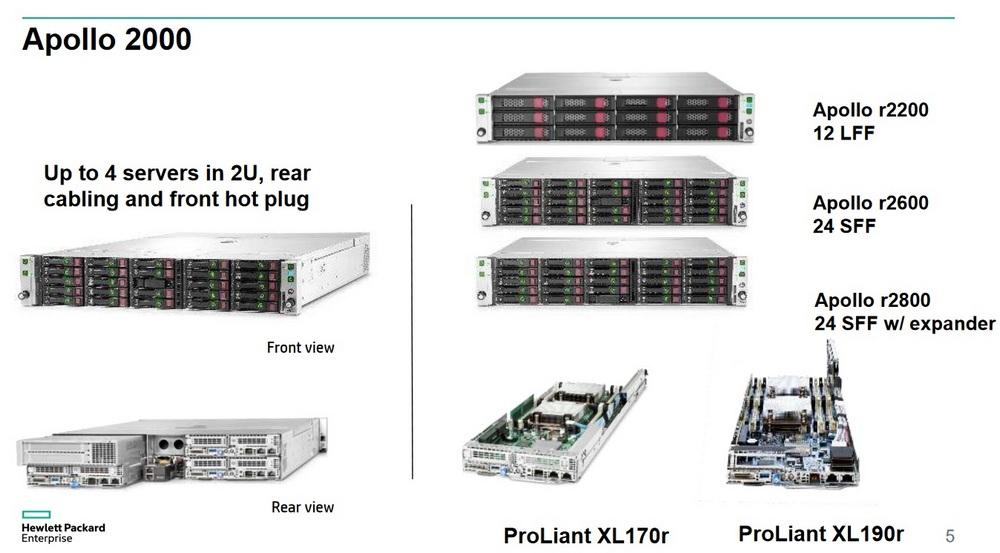
Есть еще один вариант двухюнитовых узлов. Их в шасси устанавливаются две штуки, они используются там, где помимо центральных серверов требуются еще и мощность графических ускорителей.
В результате получаем в формате шасси двух юнитов два сервера с двумя центральными процессорами и с неким компактным набором графических ускорителей. С точки зрения дискового пространства также есть несколько вариантов шасси: есть диски LFF (12 штук), которые разделяются между этими четырьмя, либо двумя узлами. 24 SFF - при этом есть вариант шасси с гибким приписыванием дисков к тому или иному узлу.
Для какой задачи этот сервер наилучшим образом подходит? Прежде всего это замена сервера DL 360 в тех условиях, где требуется более высокая плотность размещения в стойке. Например, «колокейшн» или если требуется предоставить какое-либо конкурентное и оригинальное решение, отличающееся по своим характеристикам от стандартного подхода конкурентов. Также на базе этого шасси строятся гиперконвергентные решения HPE. Есть решения simplicity на базе этого шасси. Т.е. это решение действительно подходит под компактную платформу для виртуализации и для вычислительных задач, вычислительных кластеров начального уровня.
HPE Apollo 35
Платформа Hewlett Packard Enterprise Apollo 35. Как можно догадаться по последнему в названии символу «5», следовательно, эта платформа строится на базе процессоров AMD.

Она входит в один ряд с серверами, которые постепенно набирают свою популярность, возвращая свое место в портфеле HPE после некоторого перерыва. Сейчас у AMD есть хороший портфель процессоров и количество платформ на базе AMD в портфеле HPУ будет продолжать увеличиваться. Эта платформа по сути аналогична платформе Apollo 2000, но сделана на базе процессоров AMD.

HPE Apollo 35 - это тоже двухюнитовое шасси, в которое устанавливаются 4 узла. По сути это также замена DL 325 либо DL 360, также в компактном исполнении. Ниже приведен перечень задач, для которых подходит данное решение. Платформа AMD хорошо себя зарекомендовала как платформа под виртуализацию. Но вот в таком формате (двухюнитовом и четырехузловом) сюда хорошо будут ложиться такие нагрузки, как разнородные HPC задачи, задачи, связанные с Memory Centric вычислениями и т.д.
HPE Apollo 6000
Система HPE Apollo 6000 Gen 10. Это система с воздушным охлаждением для построения вычислительных кластеров.

Иногда коммерческие заказчики тоже выбирают эти системы, если им нужно построить платформу под виртуализацию, если одновременно требуется большая инсталляция, а по каким-либо причинам HPE Synergy или Blade не подходят.
Обычно это оборудование поставляется в вычислительные кластеры, которые ориентированы на использование центральных процессоров и не подразумевают использование дополнительный мощностей, таких как графические карты. 12-ти юнитовое шасси, 24 двухсокетных узла с фронтальным доступом к дискам. С задней части расположены коммутаторы. Система HPE Apollo 6000 Gen 10 – это своего рода интегрированная фабрика, в которой есть коммутаторы: 36-портовый EDR InfiniBand, Ethernet (10-мегабитный, 40-мегабитный), интегрированный 48-портовый коммутатор OPA. Такая комбинация оборудования в таком формате позволяет значительно уменьшить кабельную инфраструктуру.
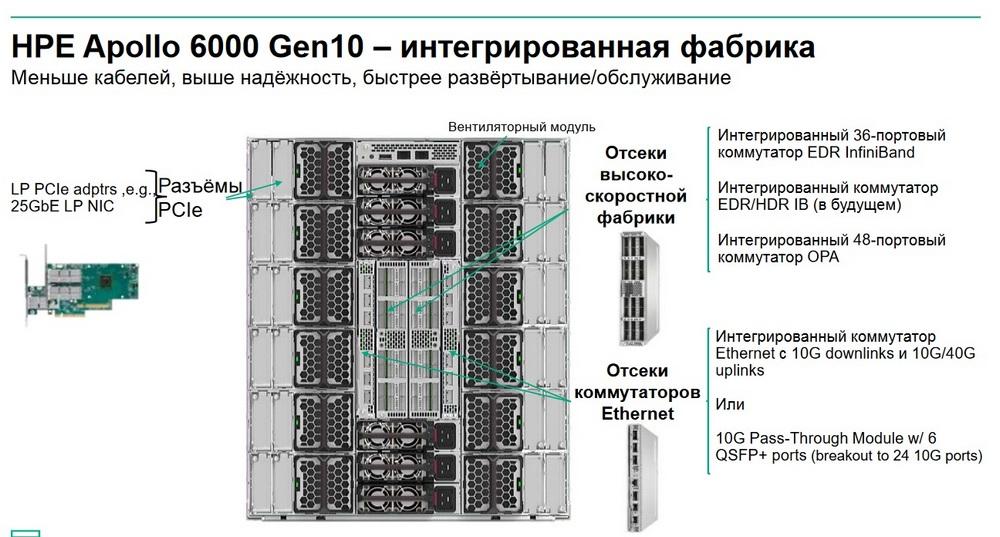
Поиски неполадок, связанных с некорректным подключением кабелей, являются рутинной и неприятной задачей как во время пуска-наладки, сборки и установки таких систем, так и для системных администраторов во время их эксплуатации. Чем меньше кабелей в HPC-кластере, тем лучше. Шасси Apollo 6000 как раз и позволяет уменьшать количество кабелей, и устраняет целый уровень кабельной инфраструктуры.
HPE SGI 8600
Система, которую вендор получил вместе с покупкой компании SGI, - это серверная платформа HPE SGI 8600 для вычислительных кластеров с водяным охлаждением. Система мощная, побила несколько мировых рекордов, и пользуется огромной популярностью, но пока только за пределами России.

В России заказчиков, готовых работать с водяным охлаждением, не много. И если вдруг возникнет необходимость побеседовать на эту тему, знайте, что в портфеле HPE такая платформа есть, и она является своего рода произведением искусства в этой сфере. Портфель такого типа систем будет расширяться, добавятся еще определенные системы для HPC, которые позволят строить систему сохранения данных в HPC-сегменте. Высокая масштабируемость – до более 10 тысяч узлов. Существенная экономия расходов на охлаждение.

HPE Apоllo 6500 Gen 10
Apоllo 6500 в России продается регулярно, причем не только в академический научный сектор, но и в коммерческий. Платформа предназначена для плотного размещения графических ускорителей.

Формат шасси - 4 юнита. Все это помещается в стандартную стойку глубиной 1 м. Высокая производительность достигается за счет топологии ускорителей (NVLink 2.0) для Deep Learning /AI. Поддерживаемые ГПУ: HPE NVIDEA Tesla V100 16/32 Гбайт, HPE NVIDEA Tesla P100 16 Гбайт и SXM2 GPU.
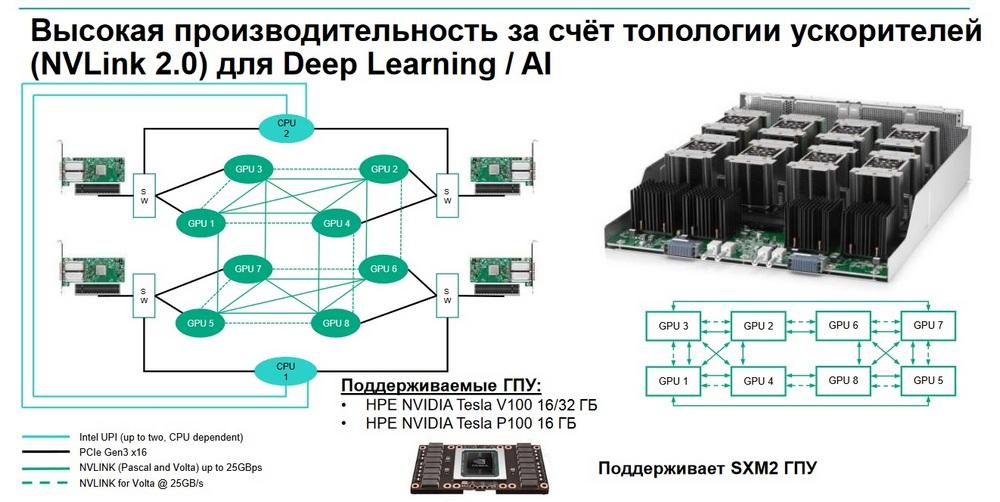
При этом 8 карт HPE NVIDEA Tesla V100 могут подключаться либо к одному центральному процессору, либо разделяться между двумя центральными процессорами в соотношении 4:1. Изменить это можно с помощью настроек в BIOS. Это дает пользователям гибкость в выборе формата вычислительных узлов, которые наиболее приемлемы для той или иной задачи.
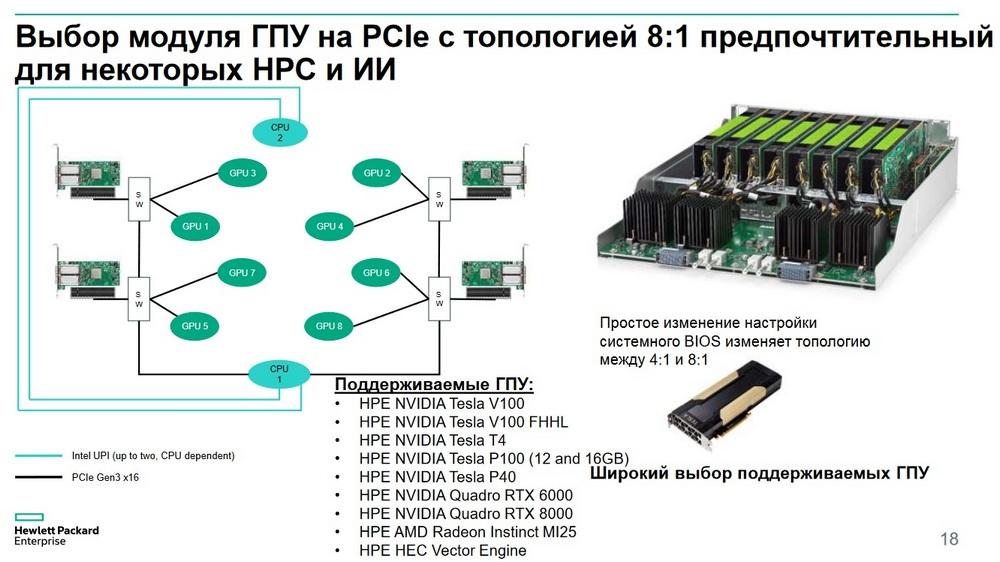
Помимо карт HPE NVIDEA Tesla V100 сюда также можно устанавливать карты HPE NVIDEA Tesla T4. С недавнего времени стало возможным в это шасси устанавливать 12 таких карт. В последнее время заказчики стали часто запрашивать большое количество карт такого типа как HPE NVIDEA Tesla T4.
HPE Apоllo 70
Эта оригинальная платформа стала первой в мире ARM-платформа, предназначенной для «тяжелых» вычислений в HPC-сегменте.

Представляет собой двухюнитовое устройство с возможностью установки 4 одноюнитовых лезвий либо двух двухюнитовых с графическими ускорителями. Платформа интенсивно используется при построении вычислительных кластеров и в инновационных лабораториях.

Кстати, если есть сомнения, насколько применима платформа ARM в принципе для тех или иных задач, на следующем слайде приведены примеры тех приложений, которые уже портированы для работы с ARM.

На Arm был построен первый мире суперкомпьютер Vanguard. В него вошло почти 2600 узлов Apоllo 70. Как он выглядит, можно увидеть на следующем слайде. В нем порядка 40 стоек с такими серверами.

Затем Александр Шумилин (Hewlett Packard Enterprise) передал слово Валерию Солоеду, менеджеру по бизнес-критичным решениям Hewlett Packard Enterprise в России.

Валерий сегодня поделится информацией о текущем статусе тех решений, которые вендор предлагаем для серверов, для центров обработки данных и с точки зрения места их установки. Он сделает упор на задачи и смысл применения графических процессоров для решения различных задач, особенно задач искусственного интеллекта и HPC.
Теперь аббревиатура HPC для вендора означает не только научные вычисления или те вычисления, которые осуществляются на суперкомпьютерных установках в научных центрах и научно-технических организациях. С точки зрения специфики, которая предъявляется к оборудованию, к сетям, к инфраструктуре, которое традиционно потреблялось только в классическом HPC, теперь стало ясно, что огромное количество задач становится очень похожими на HPC с точки зрения инфраструктуры, требований, специфики этих задач и задач, связанных с искусственным интеллектом и подзадач, связанных с глубоким обучением, с машинным обучением, с визуализацией, когда разворачивается VDI-инфраструктуры, содержащие графические процессоры.

Причем они могут играть функцию действительно ускорителей для графики, когда десктоп или приложение будут быстро что-то отрисовывать и также, как было на физическом рабочем месте, так и в тех случаях, когда виртуальное рабочее место используется как рабочее место разработчика того или иного приложения с элементами искусственного интеллекта. Поэтому теперь видно, что грань между HPC и машинным обучением, визуализацией, на самом деле очень сильно размывается и требования к решению подобного рода задач становятся очень похожим друг на друга.
Немножко статистики. Следующий слайд называется «Эволюция вычислений на GPU», но на самом деле правильнее было бы его назвать «Принятие подхода использования GPU для вычислений со стороны сообщества, со стороны заказчиков, со стороны индустрии».
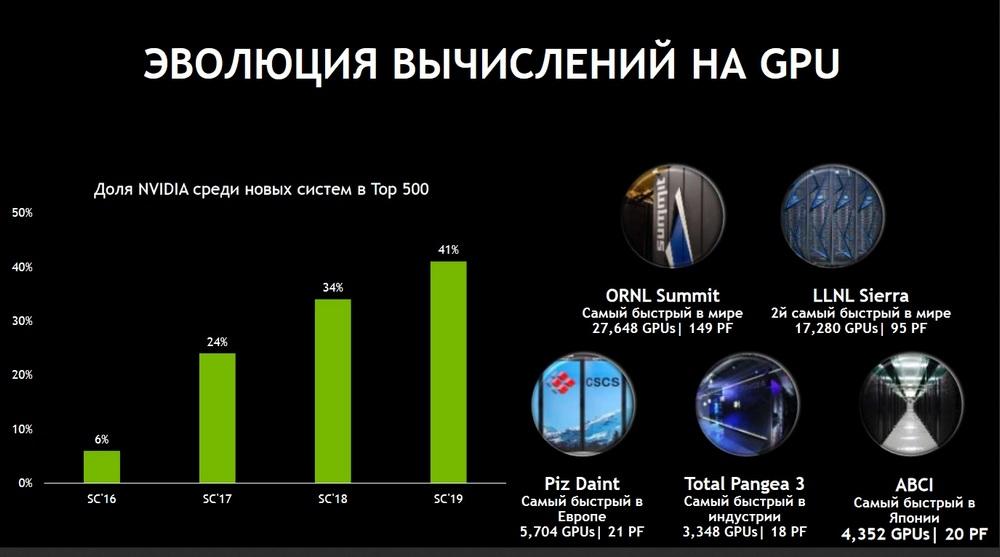
Приятно отметить, что среди всех новых систем, которые появились в последней редакции списка TOP 500 серверов, 41% систем построен с использованием графических процессоров. Если это было в диковинку еще пять-семь лет назад, то теперь GPU является привычной частью инфраструктуры центра обработки данных. Процент, это конечно, хорошо, но важно отметить, что все суперкомпьютеры, носящие имя «номер один», построены именно на базе графических процессоров. Это и самый быстрый суперкомпьютер в США и второй самый быстрый суперкомпьютер в США, и самый быстрый суперкомпьютер в Европе, в Японии, в индустрии, в России. Т.е. мы видим, когда заказчикам необходимы массивные инсталляции под большие сложные вычисления, это могут и быть вычисления, связанные с решением задач, использующих те или иные элементы искусственного интеллекта, GPU стали уже просто незаменимыми.
Еще один момент, на который хочется обратить внимание, что с одной стороны мы, как вендор, стараемся быть представленными на всех вычислительных платформах с точки зрения архитектуры центральных процессоров, а с другой стороны, нам важно чтобы у заказчика всегда была альтернатива. Мы не хотим диктовать заказчикам на какой платформе им необходимо наиболее эффективно и правильно решать свои задачи. И если до недавних пор линейка процессоров и архитектура ARM с точки зрения высокопроизводительных GPU оставалась непокрытой, то в настоящее время эта недоработка устранена. И теперь все архитектуры центральных процессоров поддерживают возможность добавления к ним GPU как ускорителя для вычислений. Выше уже упоминалось про одну из моделей в линейке HPE, которую вендоры сделали совместно, и которая содержит в себе процессоры на базе HPE NVIDEA Tesla V100. Мы надеемся, что те заказчики, для которых поддержка ARM и ARM-платформ является интересной, теперь смогут использовать все те возможности, которые предоставляют им графические процессоры.

Здесь важно отметить, когда речь идет об архитектуре программных компонентов CUDA, в начале 2019 года было объявлено, что туда вендор добавит поддержку платформы ARM. И после официального анонса теперь весь инструментарий, который был доступен на других процессорах и платформах, также стал доступен на платформе ARM+GPU.
С одной стороны, требования к инфраструктуре, к которой традиционно предъявлялись требования только как к задачам классического HPC, теперь предъявляются и к задачам, которые к классическому HPC не имеют никакого отношения, это задачи искусственного интеллекта и машинного обучения. С другой стороны, видна еще одна очень тесная связка двух подходов, которая состоит в том, что, даже если решаются действительно масштабные задачи, то они перестают быть изолированными от искусственного интеллекта, потому что даже если есть большой симулятор, который обрабатывает те или иные процессы, описанные сложной математикой, то результат этих экспериментов выливается в гигантский объем данных, результатов этого эксперимента, и, в принципе, никакого интеллекта не хватает, чтобы такой объем проанализировать за какое-то разумное время.
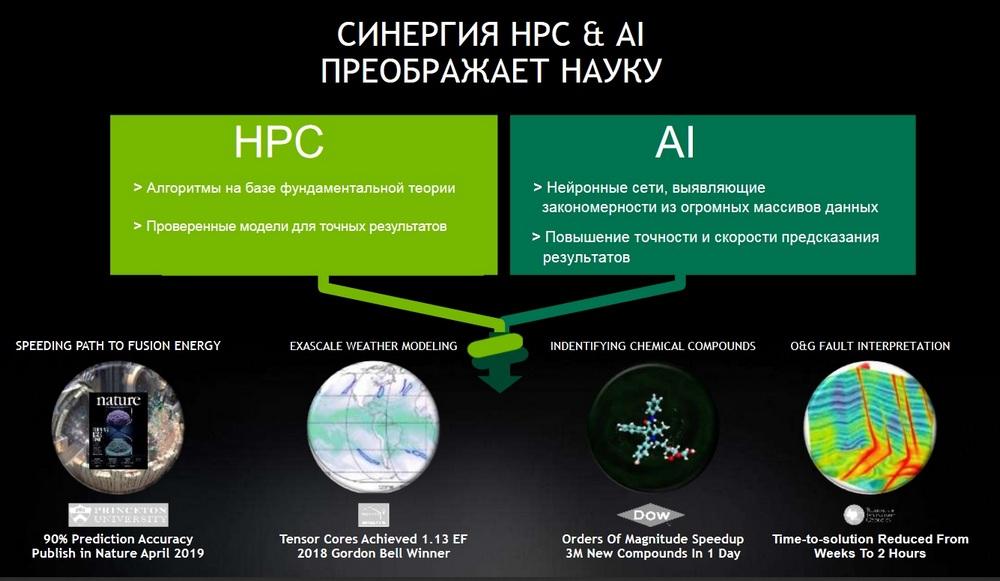
Размерность и сложность этих данных такова, что возможностей человеческого интеллекта становится недостаточно. Здесь на помощь приходит искусственный интеллект, который является следующим шагом в этом рабочем процессе, когда мы получаем метаданные моделирования с помощью классических законов физики, оптики и т.д. И в свою очередь эти данные попадают в алгоритмы, использующие те или иные элементы искусственного интеллекта, и эти алгоритмы помогают исследователям находить новые закономерности, которые не могли быть обнаружены за такой короткий срок и в таком большом объеме данных, в каком это хотелось бы сделать исследователям и потребителям классического HPC.
И здесь нужно отметить, что традиционно нас, как вендора, ассоциируют как производителя и разработчика графических процессоров, или, проще говоря, "железа". И это верно. Но при этом нужно понимать, что ничуть не меньший вклад в достижения, который приносят графические процессоры, вносит огромный объем сложного софта, который вендор разрабатывает и предоставляет сообществу и пользователям. Этот софт дальше интегрируется в те или иные программные инструменты. Это может быть поддержка как внутри классических HPC-приложений, так и поддержка разработки тренинга и применения нейронных сетей. Естественно, возникает огромное число различных библиотек для разных предметных областей. «Железо», и в нашем случае GPU, это важно, нужно, но при этом стоит помнить, что все это было бы совершенно бесполезным куском кремния, если бы не было такой большой поддержки со стороны разработчиков софта.
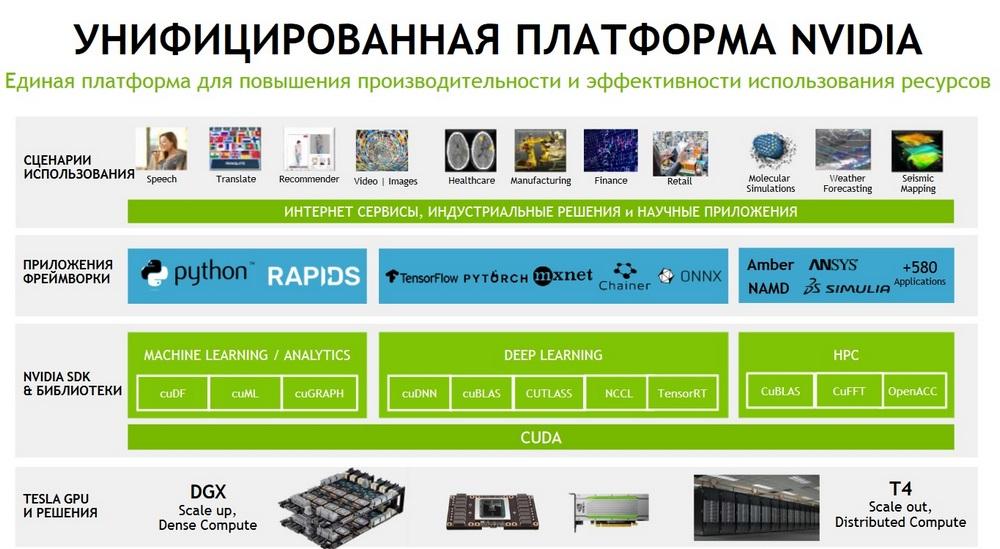
Производительность на неизменном аппаратном обеспечении
Рассмотрим интересный пример. Если взять топ из 10 классических HPC-приложений и оценить эволюцию этих приложений за последние 2 года. Важная оговорка: в течение последних 2-х лет вендор по сути не обновлял свою вычислительную архитектуру, т.е. уже больше 2-х лет используется именно архитектура Вольта, которая материализована в таких продуктах, как HPE NVIDEA Tesla V100. Таким образом при том же самом «железе» производительность этих топ-10 приложений за это время выросла в 3 раза.

Таким образом осталась прежняя аппаратная платформа, но при этом производительность прикладных приложений выросла в среднем в 3 раза. Это является иллюстрацией того, что софтверная составляющая является не менее важной, чем аппаратная. Поэтому вендор уделяет разработке софта и инструментария ничуть не меньше внимания, чем разработке новых архитектур, новых графических процессоров.
На следующем слайде очень кратко представлено семейство серверов и рабочих станций для Enterprise-заказчиков.

Если рассматривать серверы и решения для ЦОДов, то более интересна левая часть слайда, там присутствуют решения семейства Tesla, которые предназначены для использования в классических серверных решениях. И здесь можно выделить два ключевых продукта. Если нас интересует максимальная производительность, максимальная плотность упаковки, это конечно же решения TESLA V100, которые могут быть как с интерфейсом PCI-express, так и интерфейсом NVLink с одной стороны. С другой стороны, когда речь идет о максимальной «набивке» решений и задач, связанных с не HPC, например, а с задачами, связанными с виртуализацией или задач, связанных с применением технологического искусственного интеллекта, то тут лучше подойдет специализированный продукт TESLA T4. На этих двух продуктах мы остановимся позднее.
Рекомендации
На следующем слайде представлены рекомендации вендора.

Здесь значительно больше продуктов и представлено их рекомендуемое вендором позиционирование. Тем не менее здесь перечислены все основные задачи, начиная с глубокого обучения нейронных сетей (кластер для максимально быстрой тренировки сетей), классическое HPC, рендеринг (кластер для пакетной и real time обработки), VDI нагрузки, применение для Edge-компьютинга. Это рекомендации вендора, выбор же всегда остается за заказчиком. Тем не менее это некая статистика и рекомендации, которые накоплены за последние пару лет, исходя из наблюдения за тем, как продукты Tesla V100 или Tesla T4 в основном применяются заказчиками.
Tesla V100
Подробно на спецификациях продуктах Tesla V100 TENSOR CORE GPU останавливаться не будем, этот продукт на рынке уже больше двух лет.

И, несмотря на то, что его можно назвать «старичком», он по-прежнему остается востребованным заказчиками. Обратим внимание, экосистема продуктов похожа на слоеный пирог, в самом низу которого лежит архитектура графических процессоров, выше – OEM-решения компании HPE, собственно и весь софтверный инструментарий, о котором была речь ранее.
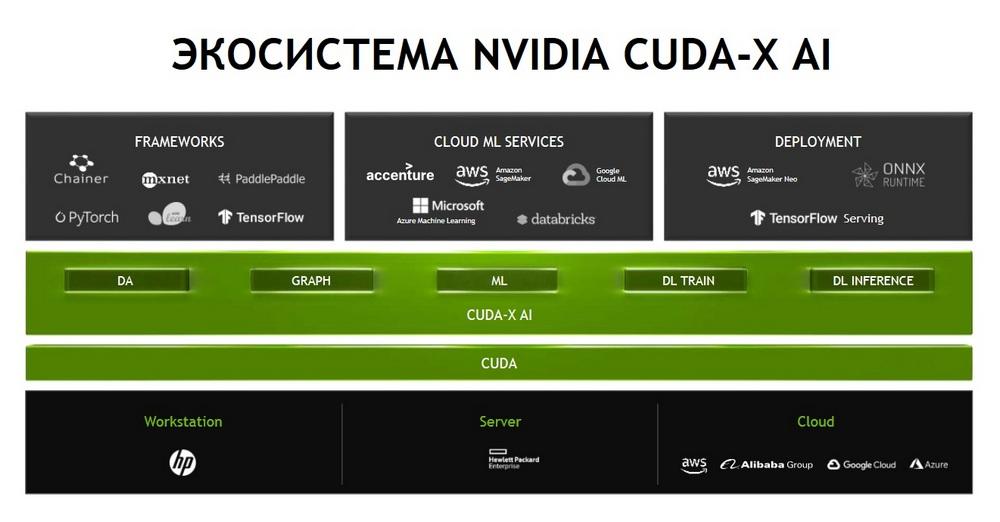
Ну и сверху находятся различные сценарии применения.
Теперь обсудим тему производительности, а также зачем и кому нужна такая производительность. Рассмотрим следующий слайд, в основу которого легло исследование, которое публично доступно от организации OpenAI. Собственно, это некая констатация факта.
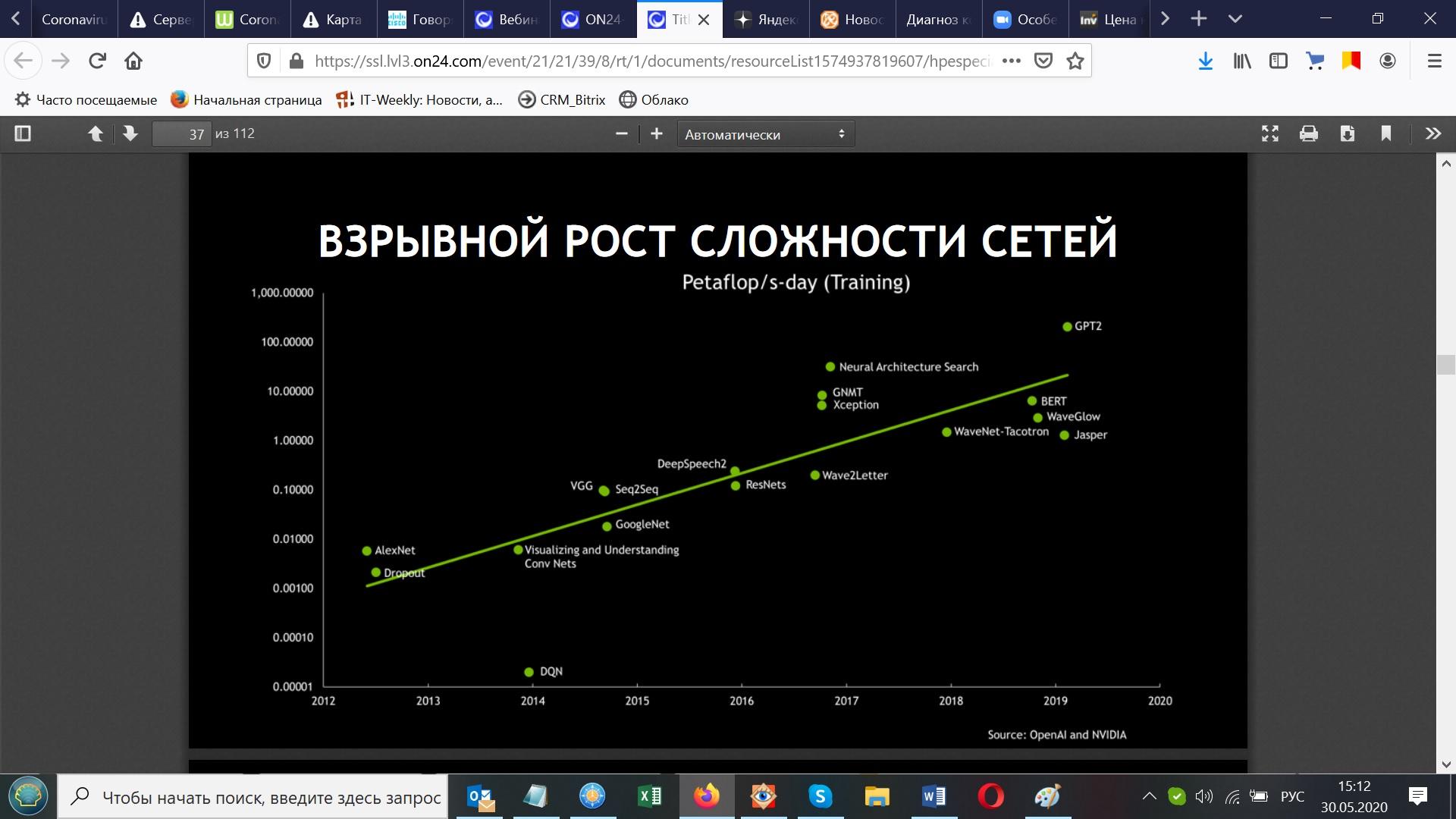
На слайде видно, что за последние 6-7 лет вычислительная сложность нейронных сетей выросла в 10 000 раз. Т.е. количество вычислений, которые нужно было в свое время сделать для классической сетки AlexNet по сравнению с архитектурами нейронных сетей, например, для распознавания голоса, выросла в 10 000 раз. Это очень хорошая иллюстрация того, почему графические процессоры настолько эффективны в решениях задач, связанных, например, с обучением нейронных сетей. Применяются они потому, что никаких других способов объективно просто не существует. Закон Мура, даже если бы он продолжал действовать, ровно так, как он описан в теории (каждые 18-20 месяцев прирастает производительность центральных процессоров примерно в 2 раза при сохранении того же энергопотребления), то за 7 лет он бы не смог бы дать такой огромный прирост. В этом состоит закономерное объяснение, почему графические процессоры так быстро нашли свое применение в сегменте, связанном с нейронными сетями.